OpenTelemetry与.NET集成概述(四)之OpenTelemetry Collector模式详解
OpenTelemetry Collector的三种模式
在OpenTelemetry 3种收集可观测数据的方式,分别是No Collector,Agent和Gateway,接下来我们会着重介绍前2种方式
No Collector 模式
这种模式是指应用程序通过集成 OpenTelemetry SDK,将遥测信号(追踪数据、指标、日志)直接导出到后端,无需经过 Collector 组件,是最简单的部署模式。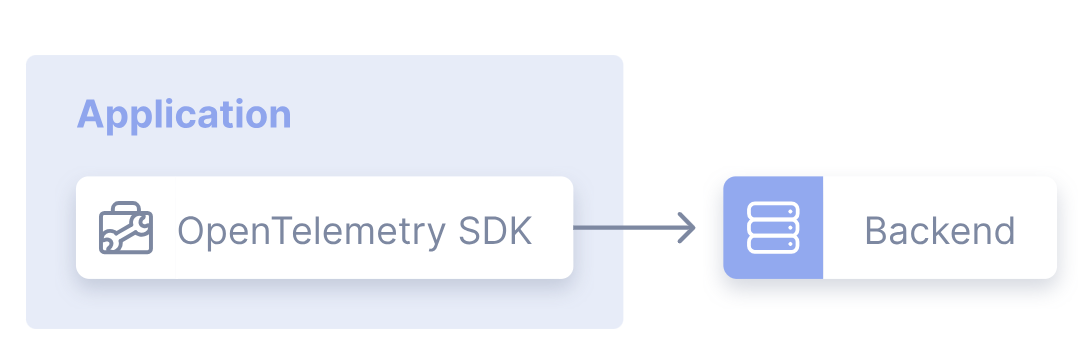
优缺点
优点
- 使用简单,尤其适用于开发和测试环境。
- 在生产环境中,无需操作额外组件。
缺点
- 当收集、处理或摄入方式发生变化时,需要修改代码。
- 应用代码与后端紧密耦合。
- 每种语言实现的导出器数量有限。当前.Net语言还支持的导出器有如下几个:
- OpenTelemetry.Exporter.Zipkin
- OpenTelemetry.Exporter.Geneva
- OpenTelemetry.Exporter.InfluxDB
- OpenTelemetry.Exporter.Instana
- OpenTelemetry.Exporter.OneCollector
- OpenTelemetry.Exporter.Stackdriver
适用场景
该模式适合对架构复杂度要求较低、需要快速验证功能的场景,如开发测试阶段或简单的生产环境。但在需要灵活处理遥测数据、支持多后端或复杂路由的场景中,可能存在局限性。
示例
现在我们先使用docker安装Zipkin:
1 | |
为我们之前的QuickStart项目安装一个新的Nuget Package:
1 | |
修改我们之前的项目,改成如下:
1 | |
跟之前的代码比较,我们只是在WithTracing的配置方法中添加了一个.AddZipkinExporter(),改动非常小。这样的改动会把对应的链路追踪数据(Traces)发送到Zipkin中,可能你也已经注意到了Trace里,我们并没有删除.AddConsoleExporter(),这也就意味着Traces数据会同时发送到两个地方:控制台和Zipkin服务端。另外我们只修改了Trace,并没有修改Metrics和Logging,这也说明了这3部分数据是互不影响的,各自有各自的配置。让我们运行这个项目,稍等一会,我们就会发现Zipkin就有数据了。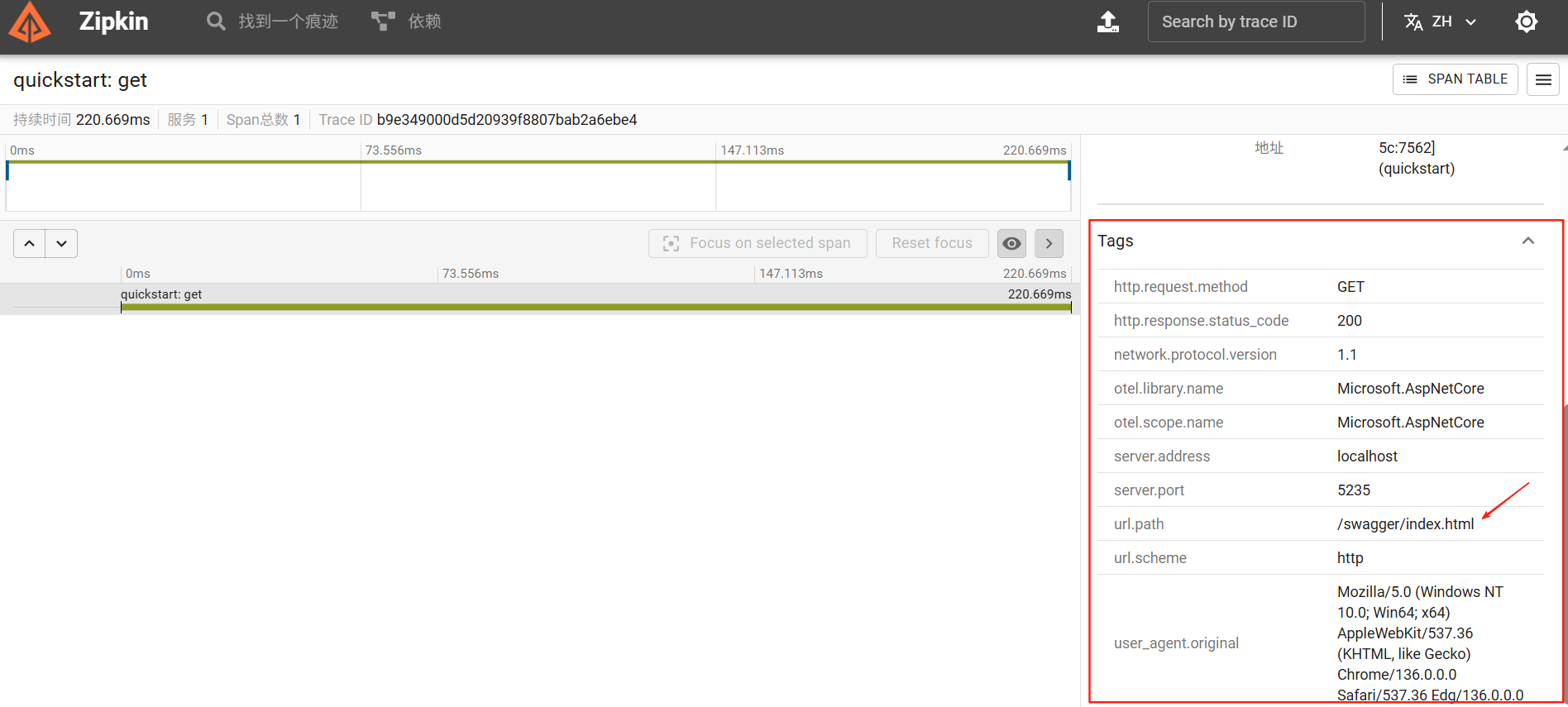
Agent 模式
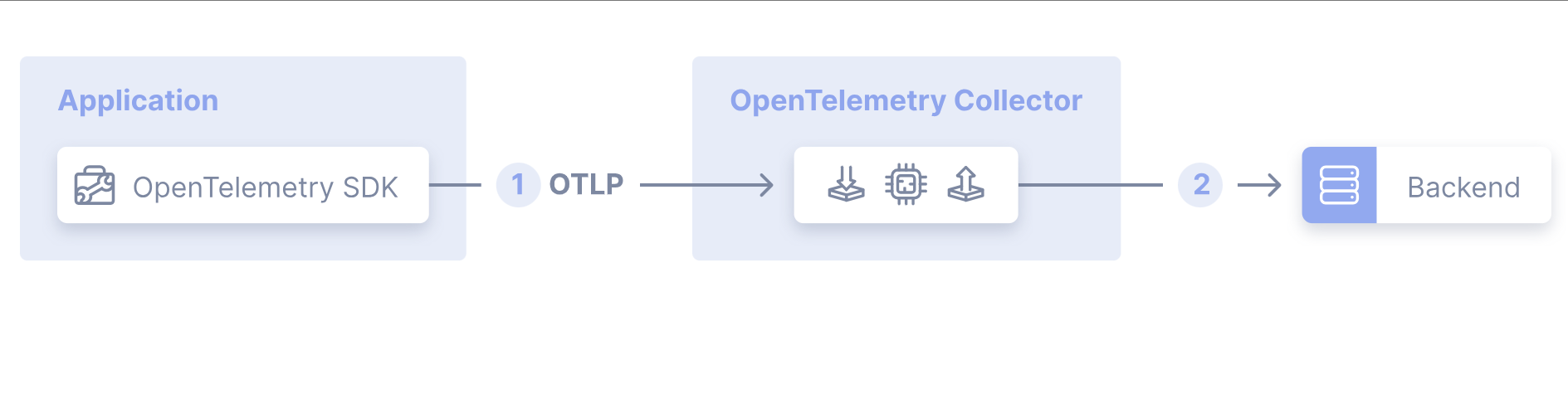
Agent 模式指应用程序通过OpenTelemetry SDK(基于 OpenTelemetry 协议 OTLP),将遥测信号(追踪数据、指标、日志)发送至与应用同机部署的 Collector 实例(如 Sidecar 容器或守护进程)。核心流程:
1 | |
关键组件交互:
- 应用端:SDK 配置为将 OTLP 数据发送至 Collector 地址(如环境变量指定端点)。
- Collector 端:接收数据后,通过配置的处理器(如批量处理)和导出器(如 Jaeger、Prometheus Remote Write)转发至一个或多个后端。
优缺点
优点
入门简单:架构清晰,适合快速搭建监控链路。
1:1 映射关系:应用与 Collector 一一对应,便于调试和单节点管理。
缺点
可扩展性受限:
人力成本:当应用节点增多时,需逐一管理每个节点的 Collector 配置。
负载压力:单节点 Collector 可能成为性能瓶颈(如高并发数据摄入)。
灵活性不足:难以支持复杂的数据路由、转换或多后端集成需求。
适用场景
- 中小型系统或开发 / 测试环境:适合需要快速验证监控功能、节点规模较小的场景。
- 同机数据处理:如 Sidecar 模式下,Collector 与应用共享资源,降低跨节点通信开销。
- 局限性场景:不适合大规模集群或需要集中式数据治理、灵活处理逻辑的生产环境。
示例
现在我们先使用docker安装otel/opentelemetry-collector
首先在你的个人目录下创建一个config.yaml文件,如果是Windows,则路径大致如下:
C:/Users/xxx/config.yaml,文件内容如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
exporters:
debug:
verbosity: detailed
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [debug]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [debug]
logs:
receivers: [otlp]
processors: [batch]
exporters: [debug]运行如下命令,启动一个collector服务:
1
docker run --name otel-collector -d -p 4317:4317 -p 4318:4318 -v C:\Users\yourname\config.yaml:/etc/otel-config.yaml otel/opentelemetry-collector-contrib:latest --config=/etc/otel-config.yaml
在我们之前的项目安装一个新的Nuget Package:
1 | |
修改我们之前的代码,如下:
1 | |
这次的改动我们把之前的ConsoleExporter和Trace中的ZipkinExporter都移除,全部替换成:.AddOtlpExporter()。这样的改动会使得应用程序中产生的3类数据全部发送到OpenTelemetry Collector,然后再由OpenTelemtry Collector根据配置转发到各个观测服务后端。为了方便演示,目前我们把所有发送的OpenTelemetry Collector的数据转发到控制台输出,在之后的文章中,我们会更改这个配置,让数据转发的真正的观测服务后端。现在我们再次运行项目,我们会在这个container的输出中看到如下的信息:
日志信息: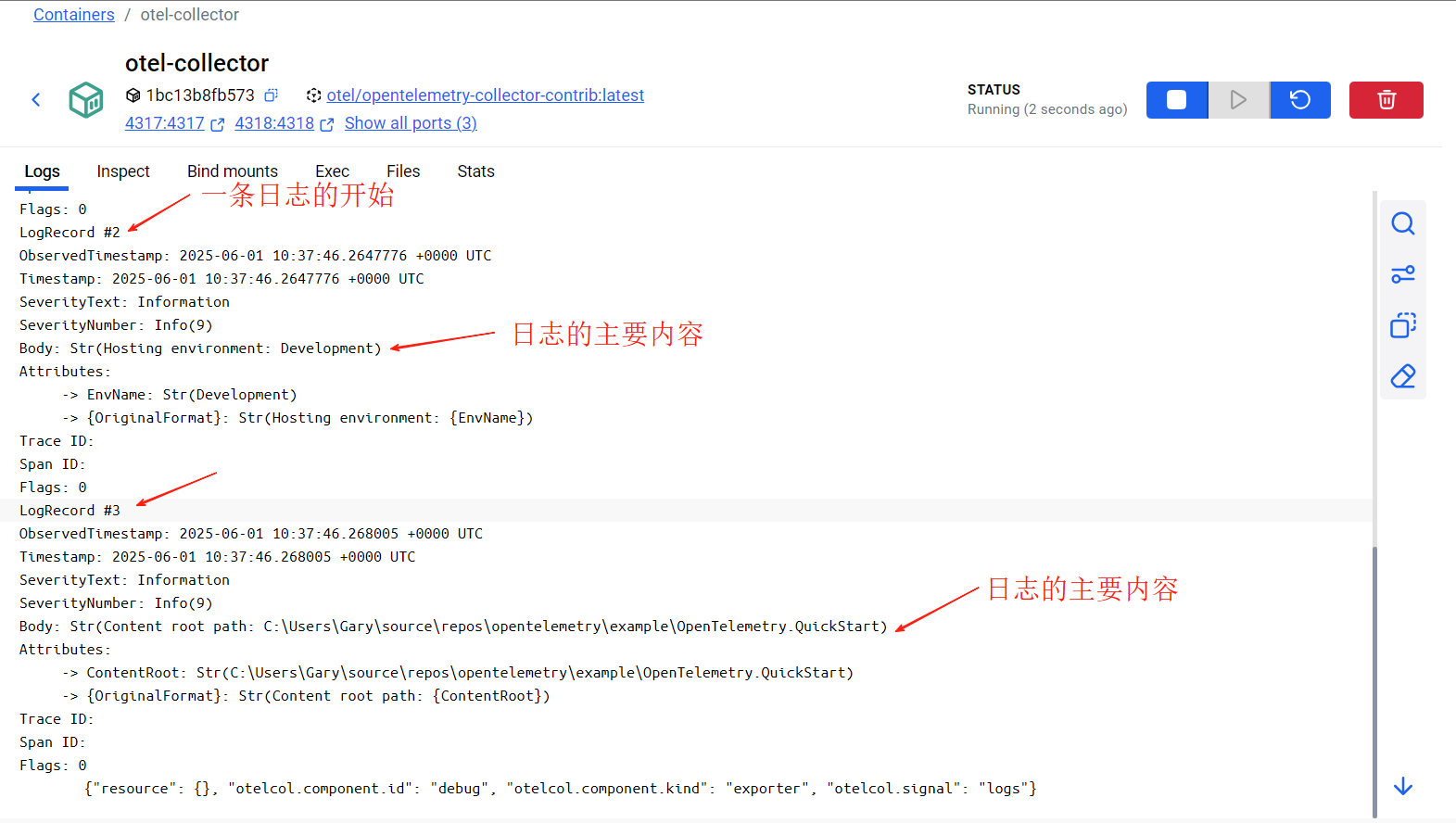
链路追踪信息: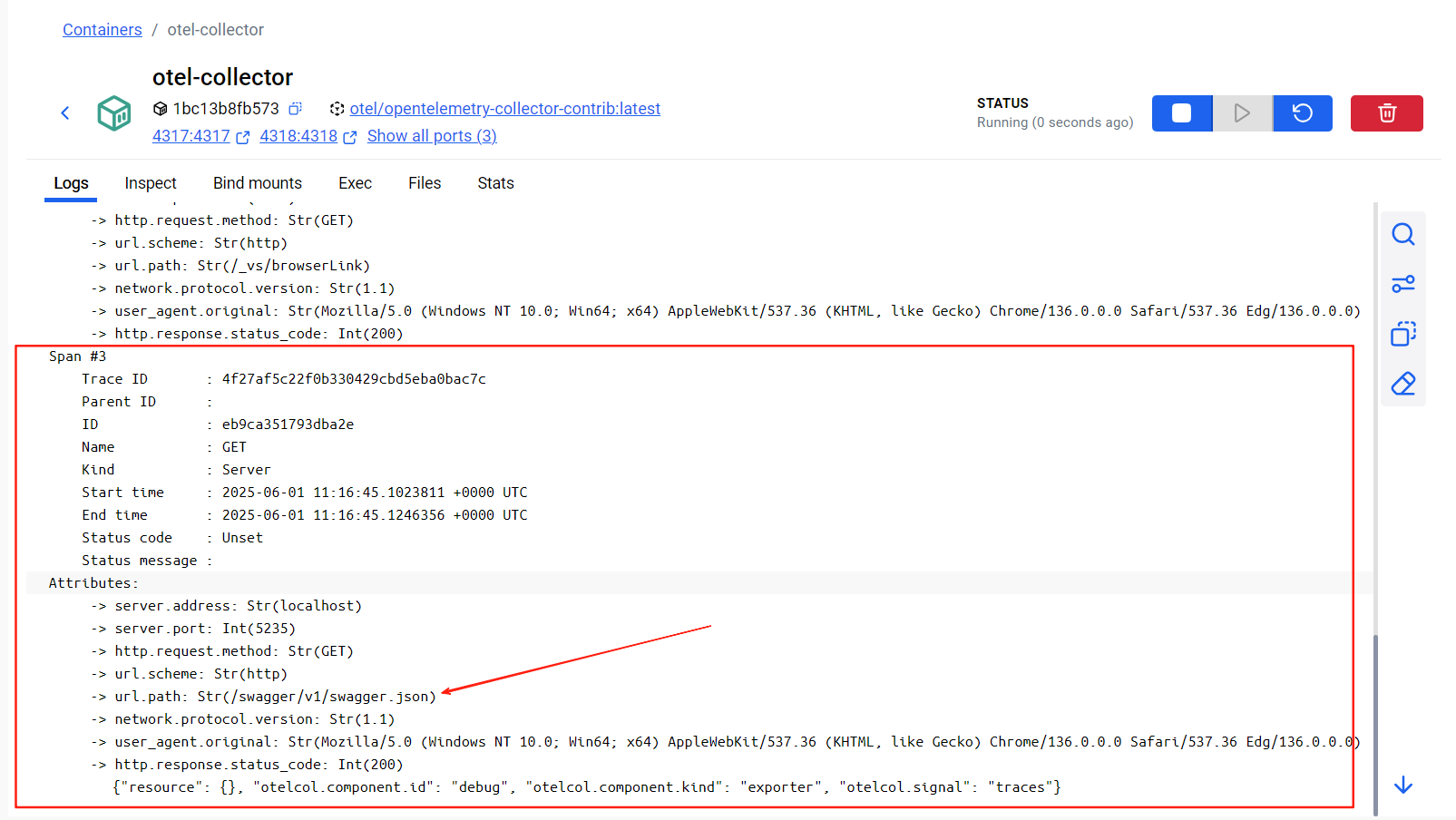
指标信息: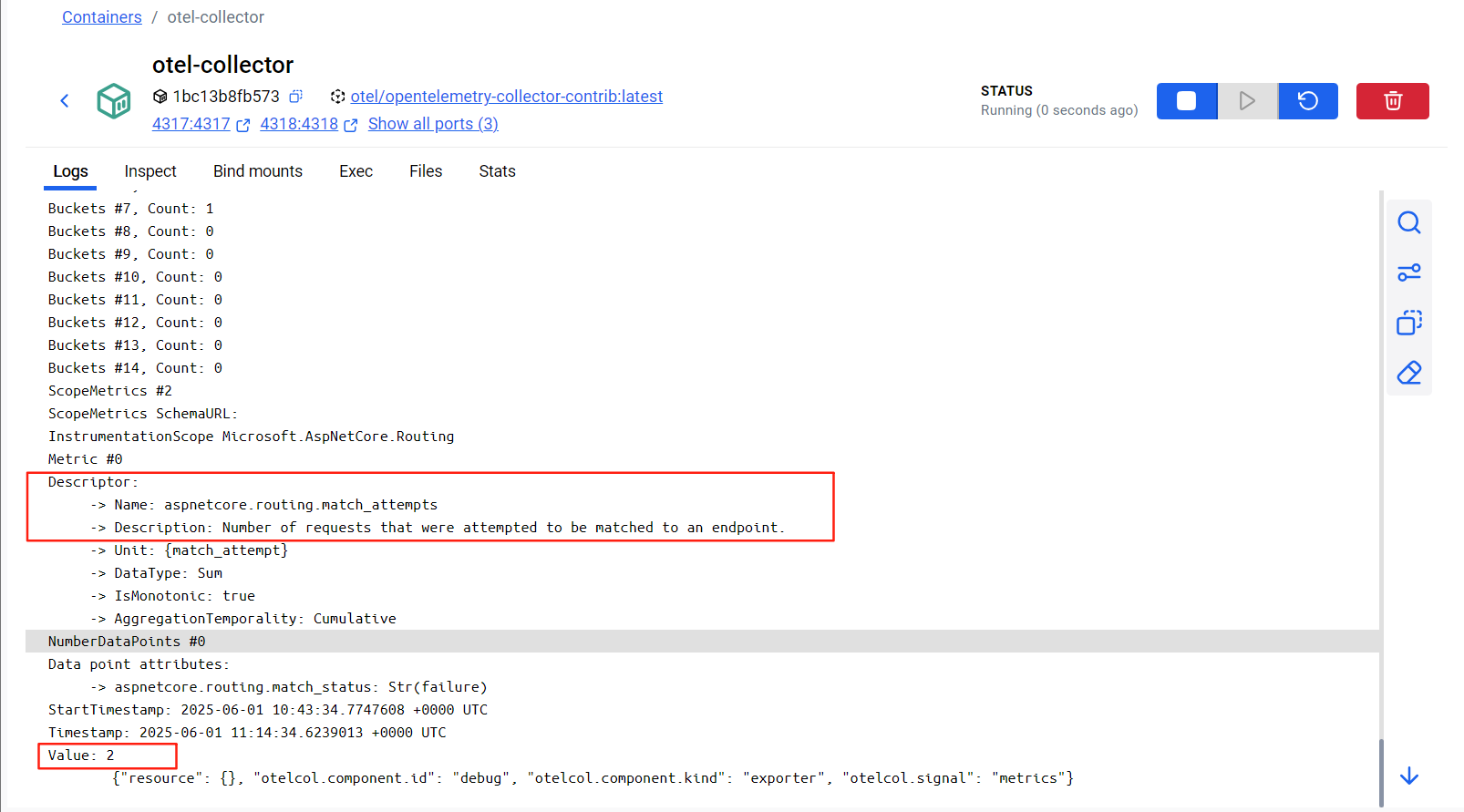
Gateway 模式
通过单一 OTLP 端点聚合来自多个应用或下游 Collector 的遥测信号,由一组独立部署的 Collector 实例(如 Kubernetes 集群中的服务)负责处理和转发数据。其核心特点是:
- 分层处理:通常分为两层 —— 第一层为网关 Collector(接收数据并负载均衡),第二层为后端 Collector(处理并导出数据至存储 / 分析系统)。
- 负载均衡:通过负载均衡器(如 NGINX)或 OpenTelemetry 内置的**负载均衡导出器(Load-Balancing Exporter)**分发流量,支持按 Trace ID、服务名等规则路由。
其核心流程:
1 | |
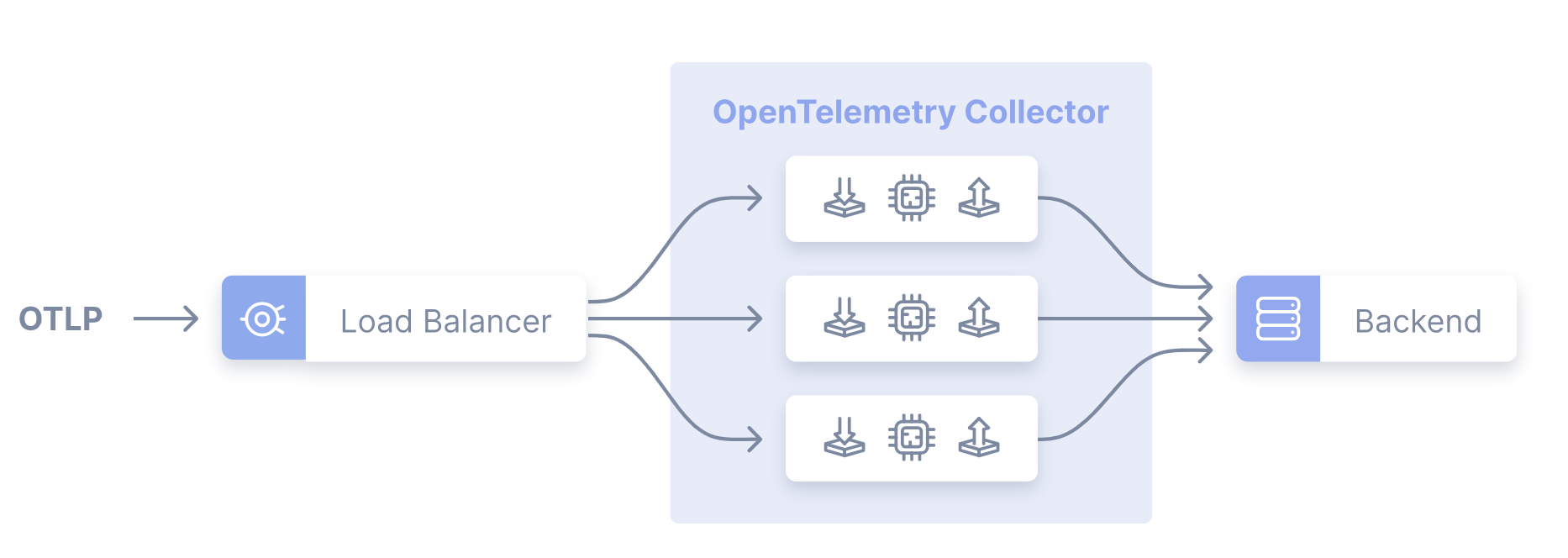
核心组件与配置示例
1. 负载均衡方案
(1)外部负载均衡器(如 NGINX)
通过 NGINX 配置 HTTP/GRPC 反向代理,将流量分发到多个 Collector 节点:
1 | |
(2)内置负载均衡导出器(Load-Balancing Exporter)
通过 OpenTelemetry 配置文件实现动态路由,支持静态列表或 DNS 解析下游 Collector 地址:
静态配置
(手动指定节点):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317 # 网关监听端口
exporters:
loadbalancing:
protocol:
otlp:
tls:
insecure: true
resolver:
static:
hostnames:
- collector-1.example.com:4317
- collector-2.example.com:5317DNS 动态解析
(自动发现节点):
1
2
3
4
5
6exporters:
loadbalancing:
resolver:
dns:
hostname: collectors.example.com # DNS解析域名获取节点IP
routing_key: service # 按服务名路由(适用于指标聚合场景)
2. 混合部署模式(Agent+Gateway)
实际生产中常结合 Agent 模式(单节点 Collector)和 Gateway 模式(集中式处理):
Agent Collector:部署在每个主机(如 Daemonset),收集本地服务和主机指标(如 CPU / 内存、文件日志)。
Gateway Collector:作为中央枢纽,接收 Agent 数据并进行过滤、采样、多后端分发等处理。
1
主机服务 → Agent Collector(本地) → OTLP → Gateway Collector集群 → 后端(如Jaeger、Prometheus)
优缺点分析
优点
集中式管理:
- 统一配置凭证、采样策略、数据过滤规则,降低维护成本。
- 支持跨集群 / 数据中心的全局视角监控。
高扩展性:
- 通过负载均衡轻松扩展 Collector 集群,应对高并发数据摄入。
- 分层架构分离数据接收与处理逻辑,灵活性强。
精准路由:
- 基于 Trace ID 或服务名路由,确保同追踪数据或同服务指标被同一 Collector 处理(如 Tail 采样、指标聚合)。
缺点
- 复杂度增加:
- 需要维护负载均衡器、多层 Collector 集群,故障排查难度提升。
- 引入额外网络跳数,可能增加数据传输延迟(尤其跨区域部署时)。
- 资源成本高:
- 多层架构导致计算、内存、网络资源消耗显著增加。
- 单写原则挑战:
- 多 Collector 处理同一指标时需确保 “单一写入者”,否则可能引发数据冲突(如 Prometheus 的时序混乱错误)。
适用场景与最佳实践
推荐场景
大规模集群 / 分布式系统:如 Kubernetes 集群、跨数据中心的微服务架构。
复杂数据处理需求:需要集中采样、过滤、转换或多后端路由(如同时导出至日志系统和监控系统)。
混合部署环境:结合 Agent 收集节点本地数据,通过 Gateway 实现全局治理。
最佳实践
避免数据冲突:
- 使用
resource detector processor为每个节点添加唯一标识(如 Kubernetes 标签)。 - 确保同一指标流由单一 Collector 实例处理,遵循 “单写原则”。
- 使用
性能监控:
- 通过负载均衡导出器的内置指标(如
otelcol_loadbalancer_backend_latency)监控 Collector 集群健康状态。
- 通过负载均衡导出器的内置指标(如
动态发现:优先使用 DNS 解析而非静态配置,提升节点扩缩容的自动化能力。
总结
Gateway 模式是 OpenTelemetry 应对大规模监控需求的核心方案,通过分层架构和负载均衡实现了数据收集的可扩展性与集中治理。尽管其部署复杂度和资源成本较高,但在需要全局视角、灵活路由和大规模数据处理的场景中不可替代。实际应用中,常与 Agent 模式结合,形成 “边缘收集 + 中央处理” 的混合架构,平衡性能与管理需求。